AI & ML Models
0.0 (0 reviews) • 0 downloads
Autism Data Disorder in Python Projects
र 1000
Autism Data Disorder in Python Projects
Technical Details
Domain : Python
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Secure Payment
Instant Download
GST Invoice
24/7 Support
About This Product
Autism Data Disorder in Python Projects
Abstract
Autism Spectrum Disorder (ASD) is a developmental disorder that affects social interaction, communication, and behavior, making early detection and analysis crucial for intervention. This project presents an Autism Data Disorder Analysis System using Python, which processes and analyzes datasets containing behavioral, demographic, and clinical information to identify patterns indicative of autism. The system employs data preprocessing, statistical analysis, and machine learning techniques to evaluate the likelihood of ASD in individuals. Python libraries such as Pandas, NumPy, Matplotlib, Seaborn, and Scikit-learn are used for data cleaning, visualization, and predictive modeling. By analyzing autism-related data systematically, the system helps healthcare professionals and researchers make informed decisions, improves early screening, and supports data-driven interventions for individuals with autism.
Existing System
In existing systems, autism detection and analysis primarily rely on manual screening tools and standardized diagnostic tests, such as ADOS (Autism Diagnostic Observation Schedule) and ADI-R (Autism Diagnostic Interview-Revised). These methods are time-consuming, require trained specialists, and may be subjective in interpretation. Some computerized systems and statistical models exist for analyzing autism data, but they often use small datasets or basic classification approaches, limiting accuracy and scalability. Existing systems typically focus on prediction without providing detailed exploratory data analysis or insights into feature correlations, making it difficult for healthcare professionals to understand underlying patterns in autism datasets.
Proposed System
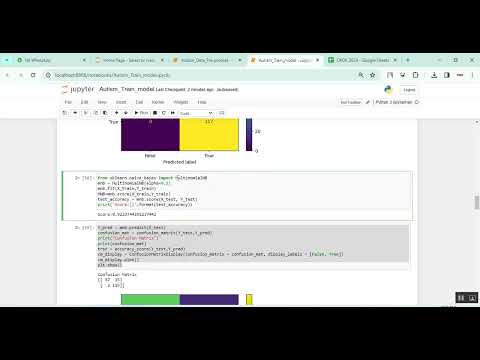
The proposed system introduces a Python-based data analysis and prediction framework for autism disorder. The system begins by importing autism datasets and performing preprocessing steps, including handling missing values, encoding categorical variables, and normalizing numerical features. Exploratory data analysis (EDA) is conducted using visualization techniques such as histograms, heatmaps, and scatter plots to understand feature relationships and trends. Machine learning algorithms such as Random Forest, Support Vector Machines (SVM), and Logistic Regression are employed to classify individuals as having autism or not based on the dataset features. Model evaluation is carried out using metrics like accuracy, precision, recall, and F1-score. A user-friendly interface using Streamlit or Flask can be incorporated to allow users to upload data, visualize patterns, and receive predictive insights. This approach ensures a systematic, data-driven, and scalable solution for autism analysis, aiding researchers, clinicians, and caregivers in early detection and intervention strategies.
Abstract
Autism Spectrum Disorder (ASD) is a developmental disorder that affects social interaction, communication, and behavior, making early detection and analysis crucial for intervention. This project presents an Autism Data Disorder Analysis System using Python, which processes and analyzes datasets containing behavioral, demographic, and clinical information to identify patterns indicative of autism. The system employs data preprocessing, statistical analysis, and machine learning techniques to evaluate the likelihood of ASD in individuals. Python libraries such as Pandas, NumPy, Matplotlib, Seaborn, and Scikit-learn are used for data cleaning, visualization, and predictive modeling. By analyzing autism-related data systematically, the system helps healthcare professionals and researchers make informed decisions, improves early screening, and supports data-driven interventions for individuals with autism.
Existing System
In existing systems, autism detection and analysis primarily rely on manual screening tools and standardized diagnostic tests, such as ADOS (Autism Diagnostic Observation Schedule) and ADI-R (Autism Diagnostic Interview-Revised). These methods are time-consuming, require trained specialists, and may be subjective in interpretation. Some computerized systems and statistical models exist for analyzing autism data, but they often use small datasets or basic classification approaches, limiting accuracy and scalability. Existing systems typically focus on prediction without providing detailed exploratory data analysis or insights into feature correlations, making it difficult for healthcare professionals to understand underlying patterns in autism datasets.
Proposed System
The proposed system introduces a Python-based data analysis and prediction framework for autism disorder. The system begins by importing autism datasets and performing preprocessing steps, including handling missing values, encoding categorical variables, and normalizing numerical features. Exploratory data analysis (EDA) is conducted using visualization techniques such as histograms, heatmaps, and scatter plots to understand feature relationships and trends. Machine learning algorithms such as Random Forest, Support Vector Machines (SVM), and Logistic Regression are employed to classify individuals as having autism or not based on the dataset features. Model evaluation is carried out using metrics like accuracy, precision, recall, and F1-score. A user-friendly interface using Streamlit or Flask can be incorporated to allow users to upload data, visualize patterns, and receive predictive insights. This approach ensures a systematic, data-driven, and scalable solution for autism analysis, aiding researchers, clinicians, and caregivers in early detection and intervention strategies.
Customer Reviews (0)
No reviews yet. Be the first!
Related Products
⭐ Featured
AI & ML Models
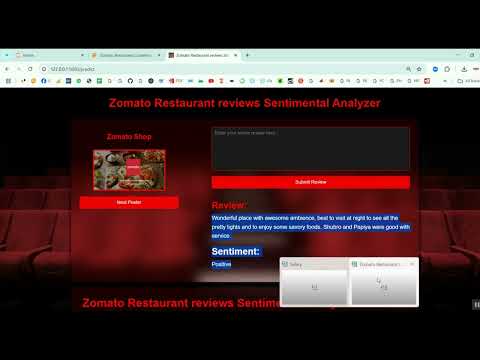
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
र 1000
⭐ Featured
⭐ Featured
AI & ML Models
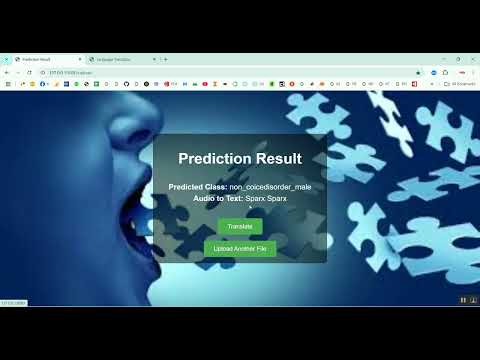
Voice Disorder Prediction using Audio Dataset in Python Projects
Voice Disorder Prediction using Audio Dataset in Python Projects
र 1000
AI & ML Models
Vitamin Deficiency Detection Using Image Processing in Python Projects
Vitamin Deficiency Detection Using Image Processing in Python Projects
र 1000